Pernahkah Anda bertanya-tanya bagaimana Google bisa menemukan artikel baru yang baru saja Anda terbitkan hanya dalam hitungan jam, atau bahkan menit?
Di tengah miliaran halaman web yang ada di jagat internet, Google seolah-olah memiliki "indra keenam" yang tahu persis kapan ada konten baru yang muncul.
Rahasia di balik kecepatan tersebut terletak pada sebuah proses teknis yang disebut crawling. Secara sederhana, crawling adalah proses di mana mesin pencari (seperti Google atau Bing) mengirimkan perangkat lunak otomatis yang disebut bot atau spider untuk menelusuri, memindai, dan "membaca" setiap sudut konten yang ada di internet.
Memahami cara kerja proses ini sangatlah krusial bagi siapa pun yang ingin websitenya sukses. Sebab, perlu Anda ingat: tanpa crawling, website sebagus dan secantik apa pun tidak akan pernah muncul di hasil pencarian.
Dalam artikel ini, kita akan mengupas tuntas apa itu crawling, bagaimana cara kerjanya, serta langkah-langkah praktis agar website Anda lebih mudah ditemukan oleh Googlebot.
Baca Juga: Apa Itu Search Query? Jenis, dan Bedanya dengan Keyword
Apa Itu Crawling? (Deep Dive)
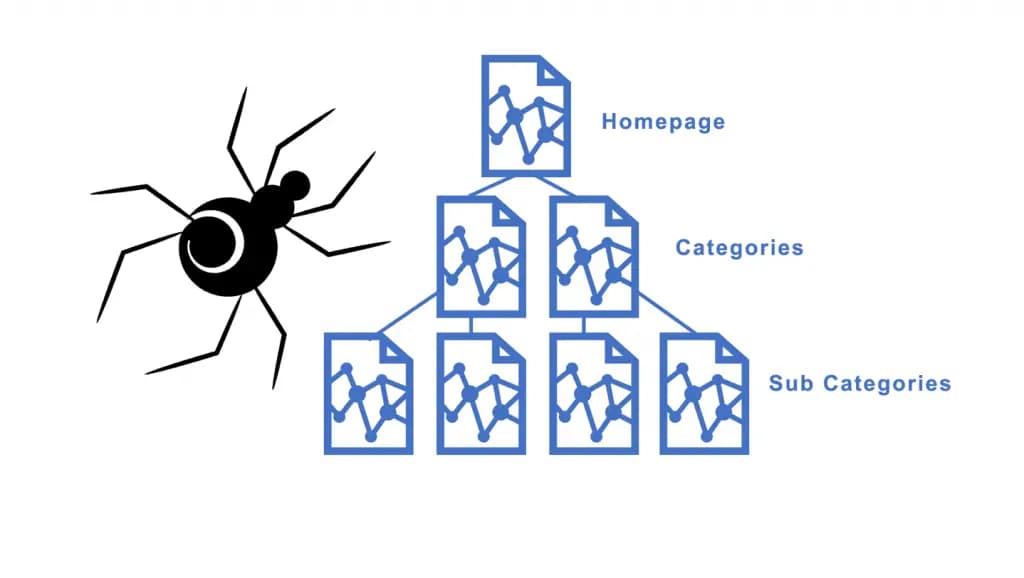
Crawling adalah proses perayapan atau penjelajahan yang dilakukan oleh mesin pencari untuk mengumpulkan informasi dari seluruh web yang bersifat publik.
Proses ini dijalankan oleh program komputer otomatis yang dikenal sebagai Web Crawler, Spider, atau secara spesifik pada Google disebut sebagai Googlebot.
Bayangkan internet sebagai jaring laba-laba yang tak berujung, di mana setiap titik persimpangan adalah sebuah halaman website.
Tugas Googlebot adalah terus bergerak dari satu titik ke titik lainnya melalui koneksi yang kita kenal sebagai link (tautan).
Tanpa adanya tautan, sebuah halaman akan terisolasi dan sulit ditemukan oleh para "penjelajah" digital ini.
Apa yang Dilakukan Bot Saat Melakukan Crawling?
Saat bot mengunjungi sebuah website, mereka tidak hanya sekadar "mampir". Ada beberapa aktivitas utama yang dilakukan secara simultan:
Pemindaian Kode: Bot akan membaca kode HTML, CSS, hingga JavaScript untuk memahami struktur dan tampilan halaman.
Identifikasi Konten: Bot menganalisis teks, judul (heading), deskripsi gambar (alt-text), hingga metadata untuk memahami konteks informasi yang disajikan.
Penemuan URL Baru: Bot akan mencatat setiap tautan yang ada di halaman tersebut. Tautan inilah yang kemudian menjadi "peta" bagi bot untuk melanjutkan perjalanan ke halaman berikutnya atau bahkan ke website lain.
Untuk memudahkan pemahaman tentang crawling ini, bayangkan sebuah perpustakaan raksasa yang setiap harinya menerima kiriman ribuan buku baru tanpa henti.
Crawling adalah tindakan seorang pustakawan yang berkeliling memeriksa setiap truk pengantar untuk melihat buku apa saja yang baru tiba.
Pustakawan tersebut akan membuka sampulnya, membaca ringkasannya, dan mencatat judulnya.
Sebelum buku tersebut disusun rapi di rak (proses indexing), sang pustakawan harus memastikan bahwa buku tersebut memang ada dan dapat diakses. Begitu pulalah cara kerja Google terhadap website Anda.
Perbedaan Crawling, Indexing, dan Ranking
Bagi banyak orang yang baru terjun di dunia SEO, istilah crawling, indexing, dan ranking sering kali dianggap sebagai satu hal yang sama.
Padahal, ketiganya adalah tahapan berbeda yang saling berkesinambungan. Tanpa melewati tahap pertama, mustahil sebuah halaman bisa sampai ke tahap terakhir.
Untuk memudahkan Anda, mari kita bedah satu per satu:
1. Crawling (Penemuan)
Seperti yang telah dibahas sebelumnya, ini adalah tahap awal di mana Googlebot "menjelajahi" internet untuk menemukan halaman-halaman web.
Fokus utamanya adalah penemuan. Googlebot mencari tahu apakah ada halaman baru, atau apakah ada perubahan pada halaman lama (seperti pembaruan konten atau link yang mati).
2. Indexing (Penyimpanan)
Setelah sebuah halaman di-crawl, langkah selanjutnya adalah pengindeksan. Dalam tahap ini, Google akan menganalisis konten halaman tersebut (kata kunci, gambar, video, dan lain-lain) untuk memahami apa isi halamannya.
Jika dianggap layak, halaman tersebut akan disimpan dalam Google Index, sebuah database raksasa yang berisi semua halaman web yang telah ditemukan Google.
Catatan: Tidak semua halaman yang di-crawl akan otomatis masuk ke index, terutama jika kontennya dianggap duplikat atau berkualitas rendah.
3. Ranking (Penampilan)
Tahap terakhir adalah pemeringkatan. Ketika seseorang mengetikkan kata kunci di kolom pencarian, Google akan menyisir indeksnya untuk menemukan halaman yang paling relevan dan berkualitas paling tinggi.
Google menggunakan ratusan faktor algoritma untuk menentukan halaman mana yang layak menempati posisi teratas. Di sinilah persaingan SEO yang sesungguhnya terjadi.
Bagaimana Cara Kerja Crawling?
Proses kerja crawler atau spider sangat sistematis dan masif. Mesin pencari seperti Google mengoperasikan ribuan bot secara bersamaan untuk memastikan miliaran halaman web di seluruh dunia dapat terdata dengan cepat dan efisien.
Berikut adalah langkah-langkah dasar bagaimana proses perayapan tersebut berlangsung:
1. Mengakses Daftar URL (The Starting Point)
Proses ini dimulai dengan crawler mengakses daftar URL yang sudah dikenal sebelumnya. Daftar ini biasanya mencakup situs-situs web terkenal, portal berita yang sering diperbarui, atau halaman yang sudah ada dalam database mesin pencari. Selain itu, bot juga akan mencari URL baru yang dikirimkan oleh pemilik web melalui Sitemap.
2. Mengikuti Tautan (Following Links)
Inilah inti dari proses perayapan. Setelah mengakses halaman pertama, crawler akan membaca seluruh konten di halaman tersebut dan mengikuti semua tautan (links) yang ditemukan. Tautan tersebut akan membawa bot ke halaman baru di dalam situs yang sama maupun ke situs web yang berbeda.
Untuk lebih memahami cara kerja ini, bayangkan alur berikut:
Crawler mulai dengan mengunjungi Halaman A1 di Situs Web A.
Di halaman A1, crawler menemukan tautan menuju Halaman A2.
Crawler kemudian bergerak mengunjungi Halaman A2.
Di halaman A2, ia menemukan tautan luar yang mengarah ke Halaman B1 di Situs Web B.
Crawler menyeberang dan mengunjungi Halaman B1, lalu mencari tautan lain di sana untuk terus bergerak.
Proses ini menciptakan efek berantai yang membuat crawler terus berpindah dari satu halaman ke halaman lain, dan dari satu situs ke situs lain tanpa henti.
3. Memeriksa dan Menganalisis Konten
Sembari menjelajah, crawler bertugas melakukan "inspeksi" mendalam. Bot akan menganalisis semua elemen yang ada di setiap halaman, termasuk:
Teks: Judul, paragraf, dan kata kunci yang digunakan.
Gambar & Video: Informasi melalui alt-text atau deskripsi file.
Elemen Teknis: Kode HTML dan struktur data yang membantu bot memahami konteks informasi.
Semua informasi yang dikumpulkan ini kemudian akan dikirim dan disimpan ke dalam database mesin pencari.
4. Siklus Pengulangan dan Pembaruan
Proses crawling tidak dilakukan hanya satu kali. Setelah menyelesaikan satu siklus penjelajahan, crawler akan memulai kembali dari awal secara berkala.
Hal ini dilakukan untuk memastikan bahwa jika ada konten yang diperbarui, dihapus, atau ada halaman baru yang ditambahkan, Google tetap memiliki data yang paling akurat dan paling baru.
5. Pengiriman Data untuk Indeks
Langkah terakhir dari kerja crawler adalah mengirimkan seluruh data yang telah dianalisis ke tahap Indexing.
Di sinilah informasi tersebut diproses agar siap dimunculkan di hasil pencarian saat pengguna mengetikkan kata kunci yang relevan.
Baca Juga: Technical SEO Adalah: Pengertian, Manfaat & 10 Checklist Lengkap
Mengapa Crawling Sangat Penting untuk SEO?
Banyak pemilik website terlalu fokus pada pembuatan konten yang indah, namun lupa memastikan apakah konten tersebut bisa ditemukan oleh bot mesin pencari.
Tanpa proses crawling yang lancar, semua upaya optimasi Anda akan sia-sia.
Berikut adalah alasan utama mengapa crawling menjadi aspek paling vital dalam strategi SEO:
1. Menjamin Visibilitas di Hasil Pencarian
Logikanya sederhana: Google tidak bisa mengindeks apa yang tidak bisa ia temukan.
Jika bot mengalami hambatan saat merayapi situs Anda misalnya karena ada kesalahan teknis atau halaman yang terisolasi maka halaman tersebut tidak akan pernah masuk ke database Google.
Akibatnya, website Anda tidak akan muncul di hasil pencarian (SERP) meskipun kontennya sangat berkualitas.
2. Mempercepat Penemuan Konten Baru
Dunia digital bergerak sangat cepat. Jika Anda mempublikasikan berita atau tren terbaru, Anda tentu ingin konten tersebut segera muncul di Google.
Efisiensi crawling memastikan bahwa bot segera menemukan halaman baru Anda.
Semakin mudah situs Anda di-crawl, semakin cepat pula konten tersebut tersedia bagi audiens Anda.
3. Memastikan Data yang Muncul Selalu Terperbarui
Crawling tidak hanya tentang menemukan halaman baru, tapi juga mendeteksi perubahan pada halaman lama.
Jika Anda memperbarui harga produk, memperbaiki informasi di artikel lama, atau mengubah struktur menu, Google perlu melakukan crawling ulang untuk memperbarui informasi tersebut di hasil pencarian.
Tanpa ini, pengguna mungkin akan melihat informasi usang yang sudah tidak relevan lagi.
4. Optimalisasi Crawl Budget
Google tidak memberikan waktu tanpa batas untuk merayapi sebuah website. Ada yang disebut dengan Crawl Budget, yaitu jumlah halaman yang akan dirayapi Googlebot pada situs Anda dalam jangka waktu tertentu.
Jika situs Anda mudah di-crawl, bot bisa menjelajahi lebih banyak halaman penting.
Jika situs Anda rumit dan penuh dengan error, bot mungkin akan "pergi" sebelum sempat menemukan halaman-halaman kunci Anda.
5. Mendeteksi Kesehatan Teknis Website
Proses crawling secara tidak langsung membantu Anda memantau kesehatan website. Saat bot mencoba masuk dan menemukan banyak broken link (link rusak) atau halaman yang lambat diakses, ini menjadi sinyal negatif bagi SEO.
Dengan memastikan jalur crawling yang bersih, Anda secara otomatis meningkatkan pengalaman pengguna (user experience).
Faktor yang Mempengaruhi Proses Crawling
Googlebot memiliki keterbatasan waktu dan sumber daya saat mengunjungi sebuah situs. Oleh karena itu, Anda perlu memastikan bahwa website Anda "ramah" terhadap crawler.
Beberapa faktor teknis berikut sangat menentukan seberapa efektif dan efisien bot dalam merayapi situs Anda:
1. Kecepatan Server dan Website (Site Speed Page)
Jika website Anda membutuhkan waktu lama untuk memuat halaman, Googlebot akan membatasi jumlah halaman yang dirayapi.
Bot tidak ingin membebani server Anda yang lambat. Sebaliknya, website yang cepat memungkinkan bot untuk memproses lebih banyak URL dalam waktu yang singkat, yang secara otomatis mengoptimalkan penggunaan Crawl Budget.
2. Struktur Internal Linking
Ingatlah bahwa bot bergerak melalui tautan. Jika Anda memiliki halaman penting namun tidak ada satupun halaman lain yang memberikan link ke sana (disebut Orphan Pages), maka bot akan kesulitan menemukannya.
Struktur internal linking yang rapi dan logis membantu bot memahami hierarki situs dan menemukan konten-konten terdalam Anda.
3. Penggunaan Sitemap XML
Sitemap adalah daftar semua halaman di situs Anda yang ingin Anda indeks. Ibarat sebuah peta jalan, Sitemap membantu crawler untuk langsung menuju halaman-halaman penting tanpa harus menebak-nebak arah melalui navigasi manual. Ini adalah faktor krusial, terutama untuk website dengan ribuan halaman.
4. File Robots.txt
File ini adalah instruksi pertama yang dibaca oleh bot sebelum masuk ke situs Anda. Jika Anda salah melakukan pengaturan di file robots.txt, Anda bisa saja secara tidak sengaja "mengunci pintu" bagi Googlebot sehingga mereka tidak bisa merayapi seluruh situs. Pastikan halaman-halaman penting Anda berstatus Allow.
5. Kualitas Konten dan Duplikasi
Googlebot cukup cerdas untuk mengenali konten yang berulang atau berkualitas rendah. Jika situs Anda penuh dengan konten duplikat (double content), bot mungkin akan mengurangi frekuensi kunjungannya karena menganggap situs tersebut tidak memberikan informasi baru yang berharga.
6. Mobile Responsiveness
Saat ini, Google menggunakan Mobile-First Indexing. Artinya, Googlebot akan merayapi versi seluler (mobile) dari website Anda terlebih dahulu.
Jika versi seluler situs Anda sulit diakses atau memiliki navigasi yang buruk, proses crawling akan terhambat dan berdampak buruk pada peringkat Anda.
Cara Mengontrol Crawling di Website Anda
Meskipun Anda ingin Google menentukan konten Anda, bukan berarti Anda ingin Googlebot menjelajahi seluruh bagian website Anda.
Ada area-area tertentu yang sebaiknya tidak perlu dirayapi, seperti halaman admin, keranjang belanja, atau folder data pribadi.
Berikut adalah beberapa cara yang bisa Anda gunakan untuk mengarahkan dan mengontrol pergerakan crawler:
1. Mengoptimalkan File Robots.txt
File robots.txt adalah dokumen sederhana yang diletakkan di direktori utama website Anda. File ini berfungsi sebagai "papan instruksi" pertama yang dibaca bot sebelum masuk ke situs Anda.
Disallow: Anda bisa menggunakan perintah ini untuk melarang bot merayapi folder tertentu (misalnya: /admin/ atau /temp/).
Allow: Digunakan untuk mengizinkan bot merayapi folder spesifik di dalam direktori yang sebelumnya dilarang.
Penting: Perlu diingat bahwa robots.txt hanya melarang perayapan (crawling), namun tidak menjamin halaman tersebut tidak muncul di indeks jika ada website lain yang menautkan link ke sana.
2. Menggunakan Tag Robots (Noindex)
Jika Anda ingin bot bisa merayapi sebuah halaman tetapi tidak ingin halaman tersebut muncul di hasil pencarian, Anda bisa menggunakan Meta Tag noindex.
Tag ini diletakkan di dalam bagian <head> pada HTML Anda.
Contohnya: <meta name="robots" content="noindex">.
Cara ini jauh lebih efektif daripada robots.txt jika tujuan utama Anda adalah agar halaman tersebut tidak tampil di Google.
3. Memanfaatkan Google Search Console
Google Search Console (GSC) adalah alat komunikasi resmi antara Anda dan Google. Di sini, Anda bisa mengontrol crawling dengan beberapa cara:
Submit Sitemap: Memberitahu Google URL mana saja yang menjadi prioritas untuk di-crawl.
URL Inspection Tool: Anda bisa meminta Google untuk melakukan crawling ulang (Request Indexing) secara manual pada halaman yang baru saja Anda perbarui.
Crawl Stats Report: Memantau apakah Googlebot mengalami kendala saat mengakses situs Anda dan melihat seberapa sering mereka datang berkunjung.
4. Menangani Parameter URL
Jika website Anda adalah sebuah toko online dengan fitur filter (misalnya filter warna atau ukuran), satu produk bisa memiliki puluhan URL berbeda.
Hal ini dapat memboroskan Crawl Budget. Anda bisa menggunakan Rel Canonical untuk memberitahu bot bahwa beberapa URL tersebut sebenarnya mengarah pada satu konten inti yang sama.
Baca Juga: Apa itu Backlink? Jenis, Kriteria & Cara Mendapatkan Backlink
5. Mengatur Kecepatan Perayapan (Crawl Rate)
Jika Anda merasa proses crawling dari bot tertentu (seperti bot dari mesin pencari lain) terlalu membebani server dan membuat website menjadi lambat, Anda bisa mengatur kecepatan akses bot tersebut melalui konfigurasi di sisi server atau alat webmaster masing-masing mesin pencari.
Peringatan: Salah melakukan pengaturan pada robots.txt atau tag noindex bisa mengakibatkan seluruh website Anda hilang dari Google secara permanen. Selalu lakukan pengecekan ulang setelah mengubah pengaturan ini.
Masalah Umum pada Crawling (Dan Solusinya)
Terkadang, meskipun Anda merasa sudah melakukan segalanya dengan benar, Googlebot tetap mengalami kesulitan saat merayapi situs Anda. Mengidentifikasi masalah ini sejak dini sangat penting agar performa SEO Anda tidak merosot.
Berikut adalah beberapa masalah crawling yang paling sering ditemui beserta solusinya:
1. Kesalahan Server (5xx Errors)
Ini terjadi ketika bot mencoba mengakses situs Anda, tetapi server tidak memberikan respons. Jika server sering down atau mengalami timeout, Googlebot akan berhenti merayapi situs Anda karena dianggap tidak stabil.
Solusi: Pastikan Anda menggunakan layanan hosting yang andal dan pantau kapasitas server agar tidak kelebihan beban saat traffic sedang tinggi.
2. Halaman Tidak Ditemukan (404 Errors)
Masalah ini muncul ketika bot mengikuti sebuah tautan, namun halaman yang dituju sudah dihapus atau alamat URL-nya berubah. Menemukan terlalu banyak halaman 404 akan membuat bot menganggap situs Anda kurang terawat.
Solusi: Lakukan redirect (pengalihan) 301 dari URL lama ke URL baru yang relevan, atau pastikan semua internal link mengarah ke halaman yang masih aktif.
3. Konten Tersembunyi di Balik Formulir atau Login
Bot mesin pencari tidak bisa mengisi formulir, mengetikkan kata sandi, atau melakukan log-in. Jika konten utama Anda berada di balik sistem membership atau kolom pencarian internal, bot tidak akan pernah bisa membacanya.
Solusi: Pastikan konten yang ingin Anda indeks bersifat publik dan dapat diakses langsung melalui link standar (HTML links).
4. Crawl Trap (Jebakan Perayapan)
Jebakan perayapan adalah struktur URL yang buruk yang membuat bot berputar-putar tanpa henti dalam jumlah URL yang tak terbatas. Contohnya adalah kalender yang terus menerus menghasilkan link "Bulan Depan" secara otomatis tanpa batas tahun.
Solusi: Gunakan file robots.txt untuk membatasi bot masuk ke folder kalender atau parameter URL yang tidak perlu diindeks.
5. Masalah pada File JavaScript
Banyak website modern menggunakan framework JavaScript yang kompleks. Terkadang, bot kesulitan melakukan rendering (memproses tampilan) konten yang hanya muncul melalui JavaScript. Jika bot tidak bisa me-render, maka bot tidak bisa melihat teks atau link di dalamnya.
Solusi: Pastikan Anda menggunakan teknik Server-Side Rendering (SSR) atau Dynamic Rendering agar bot mendapatkan versi HTML yang sudah jadi.
6. Halaman Yatim Piatu (Orphan Pages)
Seperti namanya, ini adalah halaman yang tidak memiliki tautan dari halaman mana pun di situs Anda. Karena bot bergerak melalui link, halaman ini menjadi mustahil untuk ditemukan secara alami.
Solusi: Hubungkan halaman tersebut ke dalam struktur menu atau berikan internal link dari artikel lain yang relevan.
Tips Cepat: Anda bisa mengecek semua masalah ini melalui laporan "Indexing" di Google Search Console. Google akan secara otomatis memberikan daftar URL yang mengalami masalah crawling beserta jenis error-nya.
Tools atau Alat untuk Memantau Crawling
Setelah memahami betapa pentingnya proses ini, Anda tentu perlu alat untuk memantau apakah Googlebot sudah bekerja dengan benar di website Anda.
Berikut adalah beberapa alat (tools) terbaik yang bisa Anda gunakan:
1. Google Search Console (GSC)
Ini adalah alat wajib dan gratis dari Google. GSC menyediakan data paling akurat mengenai bagaimana Google berinteraksi dengan situs Anda.
Laporan Pengindeksan Halaman: Menunjukkan halaman mana saja yang berhasil di-crawl dan di-indeks, serta mana yang mengalami masalah.
URL Inspection Tool: Anda bisa memasukkan satu URL spesifik untuk melihat kapan terakhir kali Google merayapinya dan apakah ada kendala saat proses tersebut.
Crawl Stats Report: Memberikan statistik mendalam tentang seberapa sering Googlebot mengunjungi situs Anda, berapa banyak data yang diunduh, dan waktu respons server Anda.
2. Screaming Frog SEO Spider
Berbeda dengan GSC yang merupakan alat dari Google, Screaming Frog adalah software yang bisa Anda instal di komputer untuk melakukan simulasi perayapan.
Alat ini akan merayapi website Anda persis seperti yang dilakukan oleh Googlebot.
Sangat berguna untuk menemukan broken link (404), halaman yang tidak memiliki internal link, hingga masalah pada metadata secara cepat tanpa harus menunggu bot Google datang.
3. Bing Webmaster Tools
Meskipun Google adalah pemain utama, jangan lupakan mesin pencari lain seperti Bing. Alat ini menyediakan laporan serupa dengan GSC untuk memantau bagaimana Bingbot merayapi situs Anda. Sering kali, Bing memberikan wawasan teknis yang tidak ditampilkan oleh Google.
4. Botify atau Oncrawl
Untuk website skala besar (seperti e-commerce dengan ratusan ribu produk), alat kelas enterprise seperti Botify atau Oncrawl sangat membantu. Alat-alat ini mampu menganalisis log file server untuk melihat perilaku bot secara real-time dan memberikan rekomendasi optimasi Crawl Budget yang sangat detail.
5. Google Analytics (Log Analysis)
Meskipun secara teknis bukan alat crawling, Anda bisa melihat jejak bot melalui log file di server Anda (biasanya diakses melalui CPanel). Data ini menunjukkan setiap kali Googlebot meminta data dari server Anda, yang merupakan informasi paling murni tentang aktivitas perayapan.
Rekomendasi: Jika Anda baru memulai, fokuslah untuk menguasai Google Search Console. Alat ini sudah lebih dari cukup untuk memastikan website Anda "terlihat" oleh radar Google.
Memahami bahwa crawling adalah langkah pertama dalam perjalanan SEO sangatlah penting bagi setiap pemilik website. Tanpa proses perayapan yang efisien, konten berkualitas yang Anda buat tidak akan pernah sampai ke tahap pengindeksan, apalagi muncul di peringkat teratas hasil pencarian Google.
Sebagai rangkuman, berikut adalah poin-poin kunci yang perlu Anda ingat:
Crawling adalah fondasi: Ini adalah proses penemuan konten oleh bot mesin pencari melalui tautan (links).
Kecepatan dan struktur itu utama: Website yang cepat dan memiliki struktur internal linking yang baik akan lebih mudah dan lebih sering dirayapi oleh Googlebot.
Kendali ada di tangan Anda: Gunakan alat seperti Sitemap dan file Robots.txt untuk mengarahkan bot ke halaman yang paling penting.
Pantau secara rutin: Masalah teknis seperti error 404 atau gangguan server bisa menghambat proses crawling.
Optimasi teknis agar proses crawling berjalan lancar memang bisa menjadi tantangan tersendiri, terutama jika website Anda memiliki struktur yang kompleks.
Jika Anda merasa kesulitan dalam melakukan optimasi crawling atau aspek SEO lainnya, jangan biarkan website Anda kehilangan potensi trafiknya.
Ingin website Anda lebih mudah ditemukan oleh Google? Anda bisa menghubungi Digital Marketing Agency Croloze yang siap membantu proses optimalisasi SEO website Anda secara profesional dan menyeluruh.
Serahkan urusan teknis kepada ahlinya, dan fokuslah pada pertumbuhan bisnis Anda!



